
ByteDance Dévoile Seed 1.5-VL : Un Modèle d'IA Vision-Langage Révolutionnaire Qui Rivalise Avec Gemini Pro 2.5
Dans un pas de géant pour l'intelligence artificielle multimodale, l'Équipe Seed de ByteDance a lancé son dernier grand modèle vision-langage, Seed 1.5-VL. Cela marque une étape importante dans la course mondiale à l'IA. Conçu avec seulement 20 milliards de paramètres activés, Seed 1.5-VL offre des performances comparables à celles du Gemini 2.5 Pro de Google. Il établit des références à l'état de l'art (SOTA) sur un large éventail de tâches visuelles et interactives réelles, le tout avec des coûts d'inférence considérablement réduits.
🚀 Que s'est-il passé ?
Le 15 mai 2025, ByteDance a officiellement lancé Seed 1.5-VL, la dernière évolution de sa série de modèles d'IA multimodaux Seed. Pré-entraîné sur plus de 3 000 milliards de tokens de données multimodales de haute qualité (texte, images et vidéos), Seed 1.5-VL combine un raisonnement visuel avancé, la compréhension d'images, l'interaction avec les interfaces graphiques (GUI) et l'analyse vidéo en une architecture unique et optimisée.
Contrairement aux systèmes d'IA lourds, Seed 1.5-VL repose sur une architecture 'Mixture of Experts' (MoE). Elle n'active qu'un sous-ensemble de ses 20 milliards de paramètres au total pour chaque tâche. Cela améliore considérablement l'efficacité de calcul, le rendant idéal pour les applications d'IA interactives en temps réel sur ordinateurs, mobiles et systèmes embarqués.
Malgré sa taille relativement compacte, Seed 1.5-VL a obtenu des résultats SOTA dans 38 des 60 benchmarks d'évaluation publics, dont :
- 14 des 19 benchmarks de compréhension vidéo
- 3 des 7 tâches d'agent GUI
Lors des tests, il a excellé dans le raisonnement complexe, la reconnaissance optique de caractères (OCR), l'interprétation d'images, la détection à vocabulaire ouvert et l'analyse vidéo de sécurité.
Seed 1.5-VL est désormais publiquement disponible pour test via l'API de Volcano Engine et la communauté open source sur Hugging Face et GitHub.
📌 Points clés à retenir
- Maîtrise Multimodale : Gère les images, vidéos, textes et tâches GUI avec une compréhension de niveau humain.
- Efficacité Avant Tout : Seulement 20 milliards de paramètres actifs, offrant des résultats comparables à Google Gemini 2.5 Pro avec des coûts inférieurs.
- Réalisations SOTA : Leader dans 38 des 60 benchmarks publics, notamment pour les tâches vidéo et GUI.
- Applications Pratiques : Déjà testé en OCR, analyse de surveillance, reconnaissance de célébrités et interprétation d'images métaphoriques.
- Accès Ouvert : API live sur Volcano Engine, article technique sur arXiv et code sur GitHub.
🔍 Analyse approfondie
Architecture et innovations
Seed 1.5-VL est construit sur trois modules principaux :
- SeedViT Visual Encoder : Un encodeur de 532 millions de paramètres qui extrait des caractéristiques riches des images et des images vidéo.
- MLP Adapter : Fait le pont entre l'encodeur visuel et le modèle de langage en traduisant les caractéristiques image/vidéo en tokens multimodaux.
- Grand Modèle de Langage : Un LLM basé sur MoE de 20 milliards de paramètres optimisé pour l'efficacité de l'inférence.
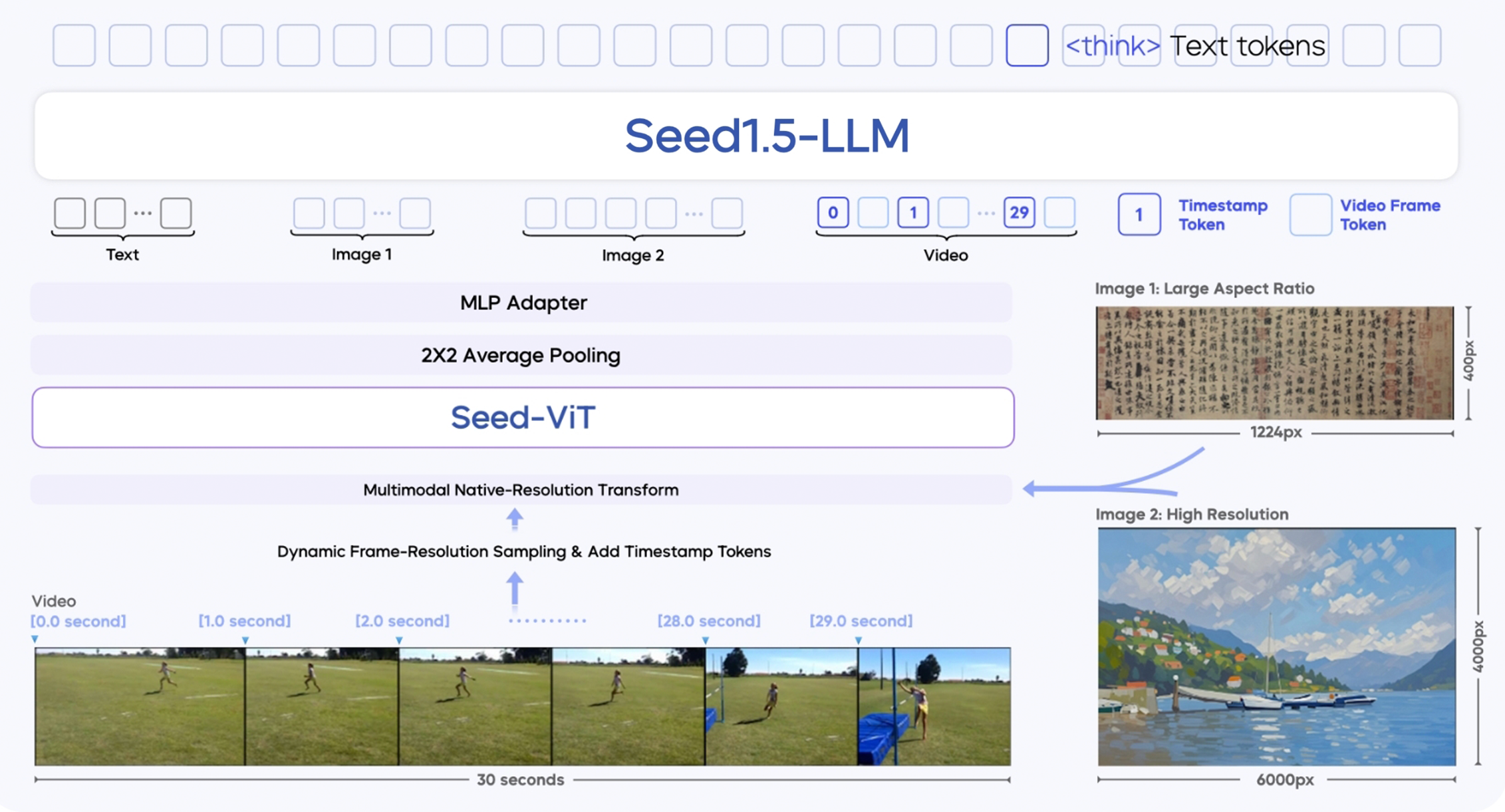
Il introduit plusieurs innovations techniques :
- Prise en charge d'entrées multi-résolutions : Maintient la qualité et la précision de l'image.
- Échantillonnage dynamique de la résolution des images : Améliore la compréhension vidéo en sélectionnant les images en fonction de la complexité du mouvement.
- Amélioration temporelle via des tokens horodatés : Permet de mieux suivre les séquences d'objets et la causalité dans les vidéos.
- Entraînement sur plus de 3 000 milliards de tokens multimodaux : Améliore la généralisation sur différents domaines.
- Ajustements post-apprentissage : Incluent l'échantillonnage par rejet et l'apprentissage par renforcement en ligne pour affiner la qualité des réponses.
Points forts
Seed 1.5-VL excelle dans :
- Les Questions-Réponses Visuelles (VQA) et l'interprétation de graphiques.
- Les tâches d'automatisation GUI, y compris le jeu et le contrôle d'applications.
- Le raisonnement interactif dans des environnements visuels ouverts.
- Les applications réelles, telles que l'identification de célébrités, la surveillance et la compréhension de métaphores.
Il est loué pour sa robustesse en conditions réelles, ce qui manque à de nombreux modèles académiques. Plusieurs évaluateurs l'ont même qualifié de "force non standard" capable de rivaliser avec o4 d'OpenAI et Gemini de Google.

Limites
Malgré ses points forts, Seed 1.5-VL n'est pas parfait :
- Défis visuels fins : A des difficultés avec le comptage d'objets sous occlusion, la similarité de couleurs ou les arrangements irréguliers.
- Raisonnement spatial complexe : Des tâches comme la navigation dans des labyrinthes ou la résolution de puzzles coulissants peuvent donner des résultats incomplets.
- Inférence temporelle : Des difficultés surviennent lors du suivi de séquences d'actions à travers les images.
Ce sont des domaines que ByteDance reconnaît et cible probablement dans les futures versions.
Contexte concurrentiel
Seed 1.5-VL est lancé au milieu d'une course à l'armement de l'IA :
- Le Gemini 2.5 Pro de Google (6 mai 2025) domine les classements multimodaux (LMArena).
- Les o3 et o4-mini d'OpenAI (17 avril 2025) font progresser l'utilisation d'outils multimodaux et l'apprentissage par renforcement.
- Des concurrents nationaux comme Tencent et Doubao ont amélioré leurs capacités d'image et vocales.
Les analystes financiers sont optimistes : les modèles d'agents et les capacités multimodales sont considérés comme les moteurs clés des applications d'IA de nouvelle génération, en particulier dans les logiciels d'entreprise, les PGI, les outils bureautiques (OA), les assistants de codage et les outils de bureau.
💡 Le saviez-vous ?
- Seed 1.5-VL peut détecter les comportements suspects dans les vidéos de surveillance – un cas d'utilisation avancé et réel que peu de modèles gèrent efficacement.
- C'est l'un des rares modèles capables de lire des images métaphoriques et d'expliquer les relations abstraites qu'elles contiennent.
- Seuls 3 modèles dans le monde (Gemini Pro 2.5, OpenAI o4, Seed 1.5-VL) sont actuellement capables de contrôle d'interface graphique (GUI) en temps réel, interactif et intermodal.
- ByteDance a réussi à rivaliser avec les performances de Gemini Pro en utilisant beaucoup moins de paramètres, démontrant des compétences d'élite en compression et optimisation de modèles.
- Seed 1.5-VL utilise une transformation native qui préserve la résolution, évitant la dégradation de la qualité courante dans les encodeurs visuels traditionnels.
Réflexions finales
Seed 1.5-VL marque une étape majeure pour ByteDance. Elle s'établit comme un leader mondial de la recherche en IA, en particulier dans les modèles fondamentaux multimodaux. Avec une efficacité de performance inégalée, une capacité robuste en conditions réelles et des réalisations SOTA dans des benchmarks clés, elle ne se contente pas de suivre Google et OpenAI – elle concurrence directement.
Alors que l'adoption de l'IA s'approfondit dans toutes les industries, des modèles comme Seed 1.5-VL seront en première ligne. Ils façonneront les agents intelligents, alimenteront l'automatisation et redéfiniront ce que les machines peuvent percevoir, comprendre et faire.
Ken, Rédacteur en chef chez CTOL : Je recommande fortement de consulter les exemples sur la page officielle Seed 1.5-VL de ByteDance – ils sont vraiment impressionnants.