
Comment choisir des GPU pour l'apprentissage profond et les modèles de langage larges
Pour sélectionner des GPU destinés aux charges de travail d'apprentissage profond, en particulier pour l'entraînement et l'exécution de modèles de langage larges (LLM), plusieurs facteurs doivent être pris en compte. Voici un guide complet pour faire le bon choix.
Tableau : Derniers LLM open source populaires et leurs exigences en GPU pour un déploiement local
| Modèle | Paramètres | Exigence VRAM | GPU recommandé |
|---|---|---|---|
| DeepSeek R1 | 671B | ~1 342Go | NVIDIA A100 80Go ×16 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ~0.7Go | NVIDIA RTX 3060 12Go+ |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ~3.3Go | NVIDIA RTX 3070 8Go+ |
| DeepSeek-R1-Distill-Llama-8B | 8B | ~3.7Go | NVIDIA RTX 3070 8Go+ |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ~6.5Go | NVIDIA RTX 3080 10Go+ |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ~14.9Go | NVIDIA RTX 4090 24Go |
| DeepSeek-R1-Distill-Llama-70B | 70B | ~32.7Go | NVIDIA RTX 4090 24Go ×2 |
| Llama 3 70B | 70B | ~140Go (estimé) | NVIDIA série 3000, 32Go RAM minimum |
| Llama 3.3 (modèles plus petits) | Variable | Au moins 12Go VRAM | NVIDIA série RTX 3000 |
| Llama 3.3 (modèles plus grands) | Variable | Au moins 24Go VRAM | NVIDIA série RTX 3000 |
| GPT-NeoX | 20B | 48Go+ VRAM total | Deux NVIDIA RTX 3090 (24Go chacun) |
| BLOOM | 176B | 40Go+ VRAM pour entraînement | NVIDIA A100 ou H100 |
Points clés à considérer lors du choix des GPU
1. Exigences en mémoire
- Capacité de la VRAM : C'est peut-être le facteur le plus critique pour les LLM. Les modèles plus grands nécessitent plus de mémoire pour stocker les paramètres, les gradients, les états de l'optimiseur et les échantillons d'entraînement mis en cache.
** Tableau : Importance de la VRAM dans les modèles de langage larges (LLM).**
| Aspect | Rôle de la VRAM | Pourquoi c'est crucial | Impact en cas d'insuffisance |
|---|---|---|---|
| Stockage du modèle | Contient les poids et les couches du modèle | Nécessaire pour un traitement efficace | Déchargement vers une mémoire plus lente ; chute majeure des performances |
| Calculs intermédiaires | Stocke les activations et les données intermédiaires | Permet les passes avant/arrière en temps réel | Limite le parallélisme et augmente la latence |
| Traitement par lots | Prend en charge des tailles de lot plus importantes | Améliore le débit et la vitesse | Lots plus petits ; entraînement/inférence plus lents |
| Prise en charge du parallélisme | Permet le parallélisme modèle/données sur plusieurs GPU | Nécessaire pour les très grands modèles (ex : GPT-4) | Limite l'évolutivité sur plusieurs GPU |
| Bande passante mémoire | Permet un accès rapide aux données | Accélère les opérations sur les tenseurs comme les multiplications matricielles | Goulots d'étranglement dans les tâches gourmandes en calcul |
- Calculer vos besoins : Vous pouvez estimer les besoins en mémoire en fonction de la taille de votre modèle et de la taille du lot.
- Bande passante mémoire : Une bande passante plus élevée permet un transfert de données plus rapide entre la mémoire du GPU et les coeurs de traitement.
2. Puissance de calcul
- Coeurs CUDA : Plus de coeurs signifient généralement un traitement parallèle plus rapide.
- Coeurs Tensor : Spécialisés dans les opérations matricielles, cruciales pour les tâches d'apprentissage profond.
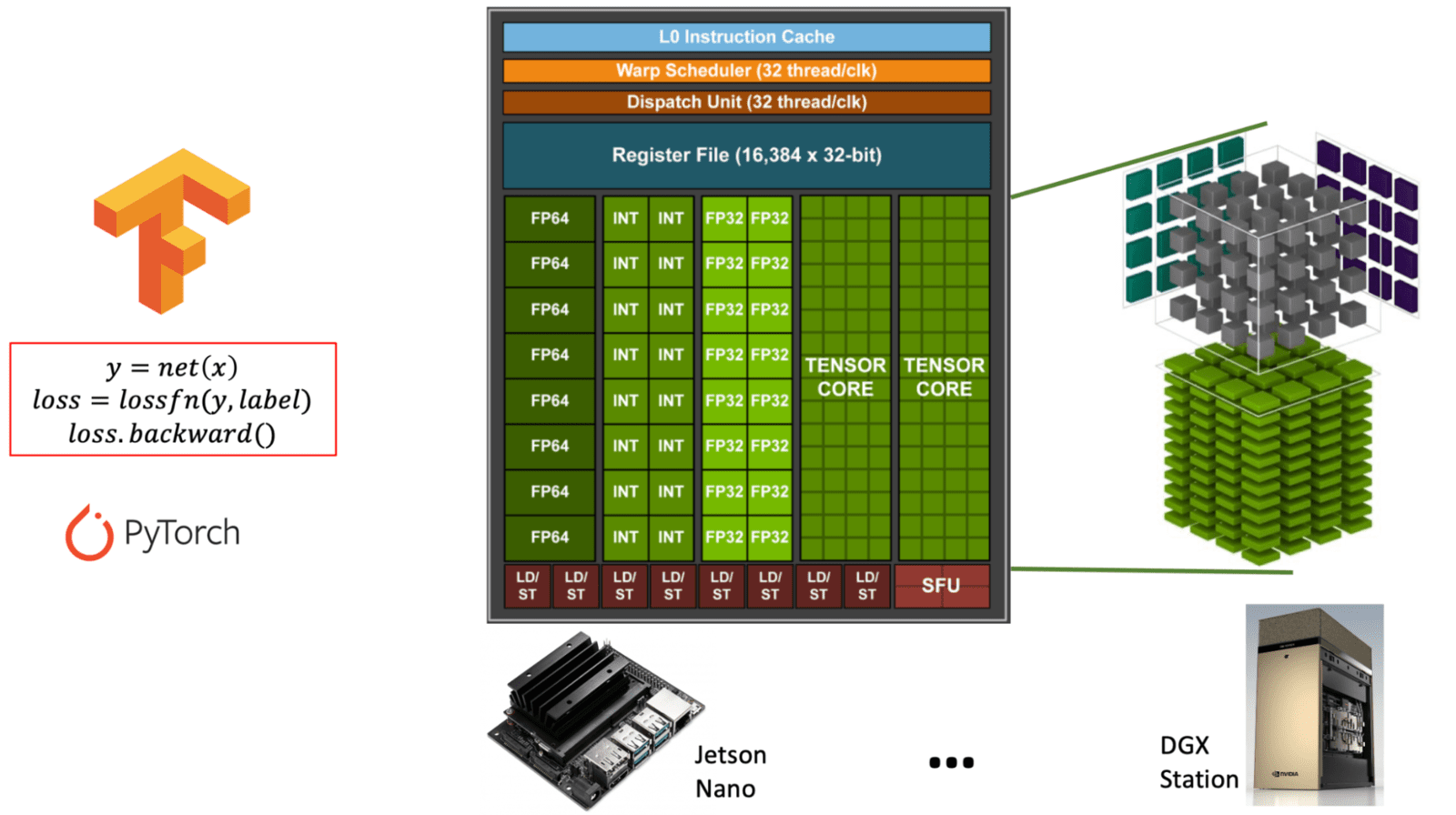
Diagramme illustrant la différence entre les coeurs CUDA à usage général et les coeurs Tensor spécialisés au sein d'une architecture GPU NVIDIA. (learnopencv.com) - Prise en charge FP16/INT8 : L'entraînement en précision mixte peut accélérer considérablement les calculs tout en réduisant l'utilisation de la mémoire.
** Tableau : Comparaison des coeurs CUDA et Tensor dans les GPU NVIDIA. Ce tableau explique le but, la fonction et l'utilisation des coeurs CUDA par rapport aux coeurs Tensor, qui sont tous deux essentiels pour différents types de charges de travail GPU, en particulier en IA et apprentissage profond. **
| Caractéristique | Coeurs CUDA | Coeurs Tensor |
|---|---|---|
| But | Calcul à usage général | Spécialisés pour les opérations matricielles (calcul sur tenseurs) |
| Usage principal | Graphismes, physique, et tâches parallèles standard | Tâches d'apprentissage profond (entraînement/inférence) |
| Opérations | FP32, FP64, INT, arithmétique générale | Multiplication-accumulation matricielle (ex : FP16, BF16, INT8) |
| Prise en charge de la précision | FP32 (simple), FP64 (double), INT | FP16, BF16, INT8, TensorFloat-32 (TF32), FP8 |
| Performance | Performance modérée pour les tâches polyvalentes | Performance extrêmement élevée pour les tâches gourmandes en opérations matricielles |
| Interface logicielle | Modèle de programmation CUDA | Accessible via des bibliothèques comme cuDNN, TensorRT, ou frameworks (ex : PyTorch, TensorFlow) |
| Disponibilité | Présent dans tous les GPU NVIDIA | Présent uniquement dans les architectures plus récentes (Volta et ultérieur) |
| Optimisation IA | Limitée | Hautement optimisée pour les charges de travail IA (jusqu'à 10x+ plus rapide) |
3. Communication entre GPU
- NVLink : Si vous utilisez des configurations multi-GPU, NVLink offre une communication GPU à GPU significativement plus rapide que le PCIe.
NVLink est une technologie d'interconnexion à haute vitesse développée par NVIDIA pour permettre une communication rapide entre les GPU (et parfois entre les GPU et les CPU). Elle compense les limitations du PCIe (Peripheral Component Interconnect Express) traditionnel en offrant une bande passante significativement plus élevée et une latence plus faible.
** Tableau : Aperçu du pont NVLink et de son objectif. Ce tableau présente la fonction, les avantages et les spécifications clés de NVLink dans le contexte du calcul basé sur GPU, en particulier pour l'IA et les charges de travail haute performance. **
| Caractéristique | NVLink |
|---|---|
| Développeur | NVIDIA |
| But | Permet une communication rapide et directe entre plusieurs GPU |
| Bande passante | Jusqu'à 600 Go/s au total dans les versions récentes (ex : NVLink 4.0) |
| Comparé au PCIe | Beaucoup plus rapide (PCIe 4.0 : ~64 Go/s au total) |
| Latence | Plus faible que le PCIe ; améliore l'efficacité multi-GPU |
| Cas d'utilisation | Apprentissage profond (LLM), calcul scientifique, rendu |
| Fonctionnement | Utilise un pont NVLink (connecteur matériel) pour relier les GPU |
| GPU pris en charge | GPU NVIDIA haut de gamme (ex : A100, H100, RTX 3090 avec limites) |
| Logiciel | Fonctionne avec les applications et frameworks compatibles CUDA |
| Évolutivité | Permet à plusieurs GPU de se comporter davantage comme un seul grand GPU |
Pourquoi NVLink est important pour les LLM et l'IA
- Parallélisme de modèle : Les grands modèles (ex : LLM de style GPT) sont trop volumineux pour un seul GPU. NVLink permet aux GPU de partager efficacement la mémoire et la charge de travail.
- Entraînement et inférence plus rapides : Réduit les goulots d'étranglement de communication, augmentant les performances dans les systèmes multi-GPU.
- Accès mémoire unifié : Rend le transfert de données entre les GPU presque transparent par rapport au PCIe, améliorant la synchronisation et le débit.
- Entraînement multi-cartes : Pour l'entraînement distribué sur plusieurs GPU, la bande passante de communication devient cruciale.
Tableau récapitulatif : Importance de la communication inter-GPU dans l'entraînement distribué
( Tableau : Rôle de la communication inter-GPU dans l'entraînement distribué. Ce tableau décrit où une communication rapide entre GPU est requise et pourquoi elle est essentielle pour un entraînement évolutif et efficace des modèles d'apprentissage profond. )
| Tâche d'entraînement distribué | Pourquoi la communication inter-GPU est importante |